
DETR & Deformable DETR
Object Detection을 ViT를 이용하여 개선하려는 시도가 많이 이루어졌다. 그 중 대표적인 논문이 DETR이 아닐까 싶다.
DETR은 ViT로 이루어져 있고, nms 등 후처리가 필요한 과정들이 제거된 모델이면서 성능도 잘 나와서 많은 관심을 받게 되었다. 다만 여기에도 단점들(느린 수렴 속도)이 존재하여 이를 개선하려는 많은 시도가 있었다. 이를 개선하려는 시도인 Deformable DETR도 살펴보려고 한다.
- 기본적인 ViT 구조 등에 대한 설명은 생략하도록 하겠다.
DETR
기본적인 구조는 아래와 같다. CNN backbone을 통해 feature들을 뽑고, 이를 ViT encoder를 통해 feature들 간의 관계를 이해하도록 학습하고, 이후 decoder에서 object query들 간의 관계를 학습하여 최종적으로 모델이 object의 위치를 파악할 수 있도록 하였다. 이 때 object query에서 bbox의 정보를 학습하도록 진행이 된다.
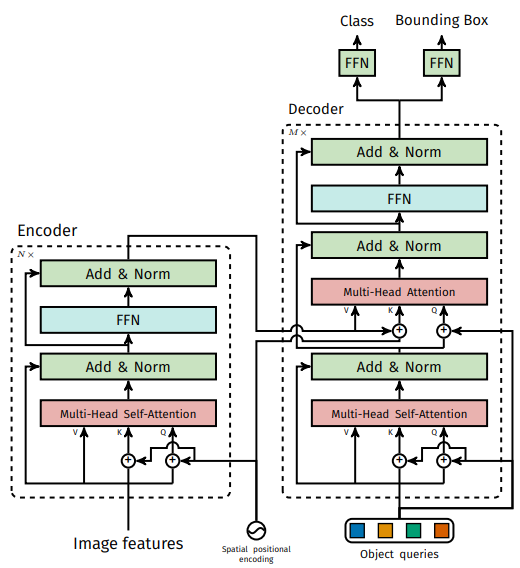
학습할 때는 bbox를 예측하는 loss가 계산되는 방식이 기존과 다른데, 아래 그림을 보면서 먼저 간단하게 이해를 해보자. 논문에서의 설명을 그대로 가져오면, decoder는 사전에 학습된 소수의 고정된 위치 임베딩을 입력으로 받는데, 이것이 object query이다. Deocder는 추가적으로 encoder 출력에 주의를 기울인다. Decoder의 각 출력 임베딩은 FFN으로 전달되며, 이 네트워크는 detection(클래스와 경계 상자) 또는 ‘객체 없음’ 클래스 중 하나를 예측하게 된다.
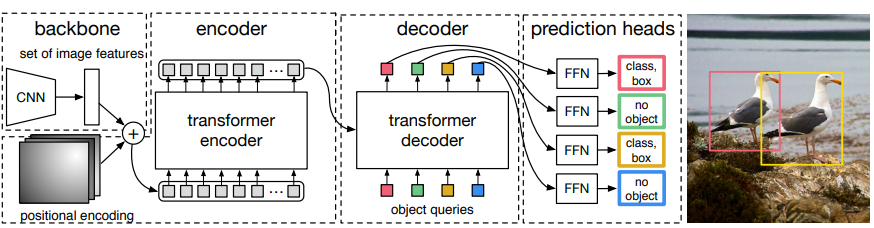
Loss Function
위에 설명에 이어서 loss function을 설명하면서 추가적으로 이야기를 해보겠다. 크게 Bipartite Matching Loss가 사용된다.
- 헝가리안 알고리즘을 도입하여, 모델의 예측과 실체 gt 사이에서 일대일 매칭을 수행한다.
- Matching cost가 되도록 학습을 진행한다.
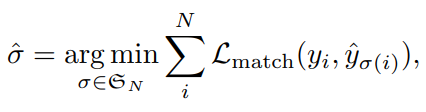
- $L_{match}$는 아래와 같다.
- 앞의 부분은 클래스 확률을 예측하는 부분이고, $L_{box}$는 L1 loss와 IoU loss의 조합이다.
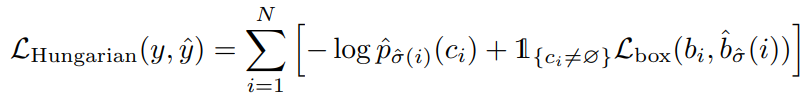
- object query는 dataset class수보다 많은 100개가 주어진다.
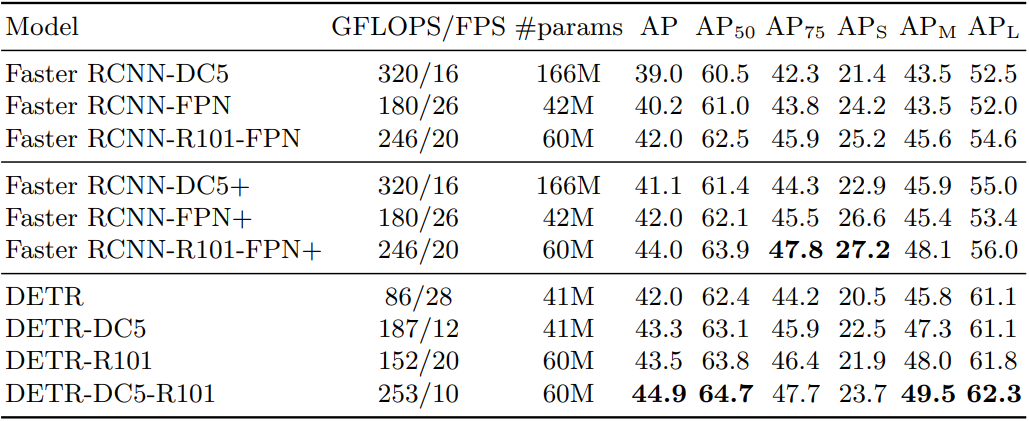
성능
- 기존의 RCNN 계열의 모델보다 좋은 성능을 냄.
- 작은 객체에서의 성능은 좋지 않음.
특징
- 앞에서 말했듯, 수렴 속도가 느리고 작은 객체에서의 성능이 좋지 않은 것은 문제가 된다. 추후의 논문들에서 많이 개선된다.
- Encoder에서는 객체를 분리하고, decoder에서는 객체의 경계 부분에 초점을 더 잘 맞추고자 함.


Deformable DETR
기존의 느린 수렴 속도와 작은 객체에서의 낮은 성능이 문제가 되었는데, 이를 해결한 논문이다. 결과부터 가져와봤는데, 기존의 DETR은 500 epoch은 가야되는데, Deformable DETR은 50에서도 비슷한 성능을 냄을 확인할 수 있다. 그리고 객체가 작을 때도 성능이 R-CNN 계열 이상으로 잘 나온다.
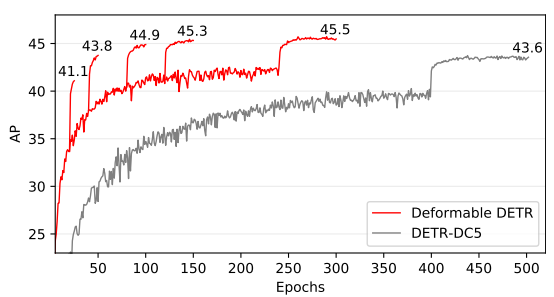
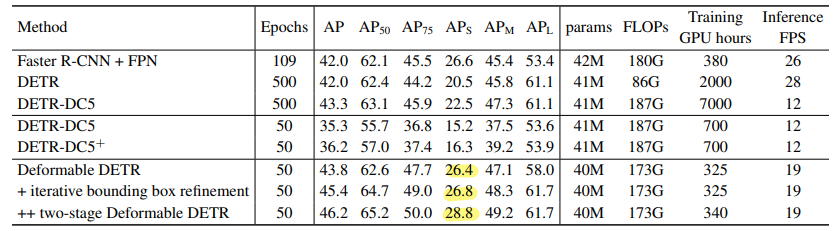
그냥 생각해봐도, CNN 계열의 모델을 사용하다 보면 계층 별로 정보를 가져오면 성능이 좋다는 것이 많이 증명되었다는 것을 떠올릴 수 있을 것이다. 또 deformable attention은 feature map에서 모든 정보를 가져오는 것이 아닌 알아야 될 영역에만 주의를 기울일 수 있게 해주는 방법이다. 이로 인해 복잡도를 떨어뜨려 multi-scale을 가능하게 하였다. 전체적인 구조는 다음과 같다.
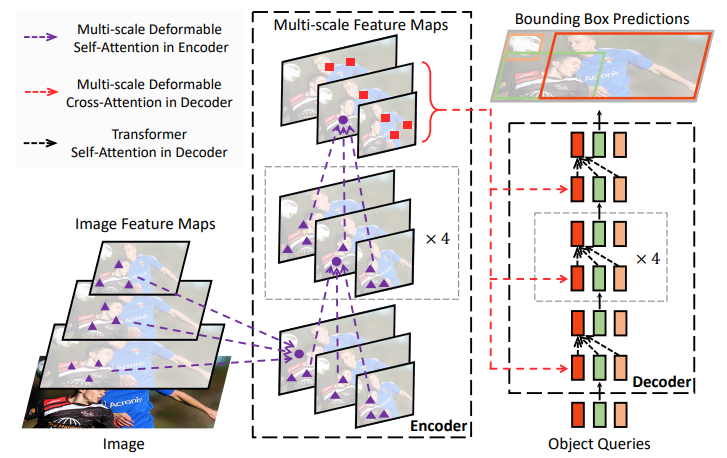
모델의 구조가 나는 이해가 어려웠어서, 세부적으로 살펴보려고 한다.
Multi-scale Feature Maps
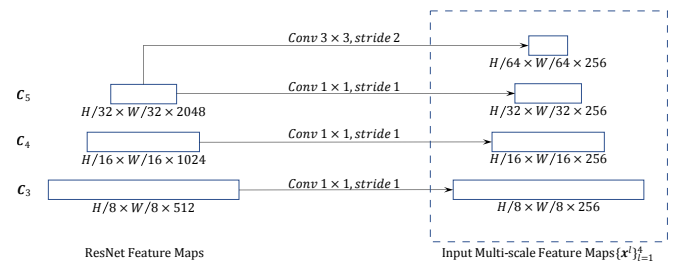
3개의 feature maps에서 4개의 정보를 추출한다. 하나는 kernel_size=3, stride=2로 같은 feature map에서 가져온다. 총 4개의 feature map들은 정규화시킨 후, 동일한 지점에서 측정할 offset 수만큼 reference point들을 추측한다. (참고로 모든 픽셀은 아님. Torch의 meshgrid를 통해 조합함)
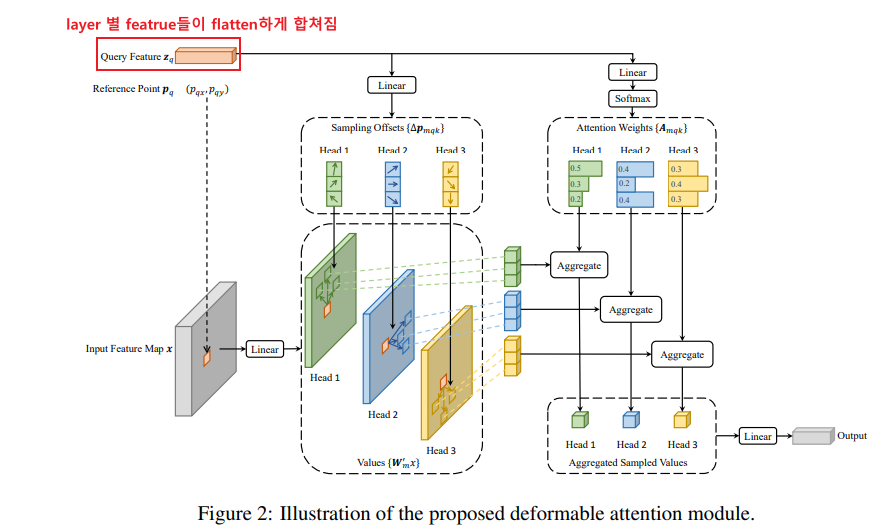
수식으로 Attention 진행 방식도 살펴보자. 2d refernce poinst $p_q$에 offset $(\Delta pmqk)$ 이 더해지고 이와 attention weight가 곱해진다. Attention weight는 합이 1이 되게끔 query feature로부터 변형되어 만들어진다.
디코더에서는 인코더에서 나온 embedding이 key, value로 사용되고 object query(여기서는 400개였나)가 query로 사용되서 attention이 수행된다. Training시에는 decoder의 모든 output이 학습에 사용되지만 inference에서는 마지막 ouput만 사용된다.
Leave a comment