
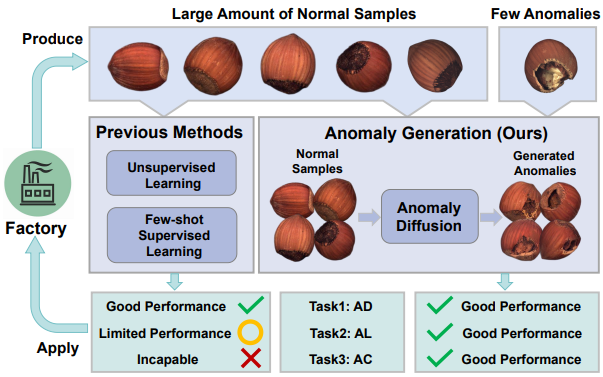
AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model
Diffusion을 이용해서 anomaly detection을 했는데 성능이 정말 잘 나왔다. 새로운 diffusion 기반의 few-shot anolmaly generation model로서, 대규모 데이터셋으로부터 학습된 latent diffusion model의 정보를 이용함.
기존의 이상 검사 알고리즘들은 오직 정상 샘플만을 이용한 비지도 학습, few-shot 지도 학습 방법론들을 주로 이용하였다. 이상 감지에는 효과적이지만, 이상 localization이나 분류 등의 task에서는 제한이 많았다. 기존의 연구자들은 두 가지 type으로 이상 데이터를 보충하는 방법론을 제안하였다.
(1) Model-free methods : random하게 crop하여 패치에 붙인다. 이는 합성 데이터의 진위성이 낮은 문제가 있다.
(2) GAN 기반의 methods : training을 위해 많은 이상 샘플들을 필요로 한다. Few-shot으로 행해진 연구들도 있지만, 생성된 이상이 진짜 같지 않다.

(3) Anomaly_Diffusion : 논문에서 제안하는 방법론. 대규모 데이터셋으로 pretrain된 LDM(Latent Diffusion Model)을 이용한다. 이를 통해 몇 개의 anomaly data만으로도 더 나은 표현을 뽑아낼 수 있다.
방법
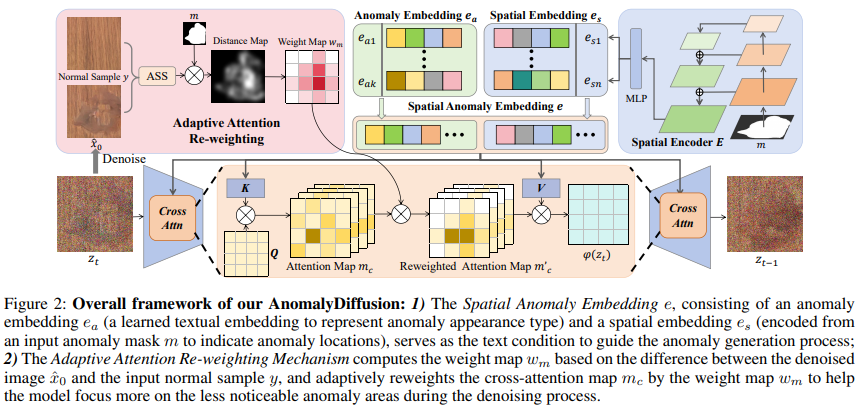
모델의 핵심은 적은 anomaly sample로부터 anomaly mask와 align된 많은 양의 anomaly data를 생성하는 것이다.
Embedding
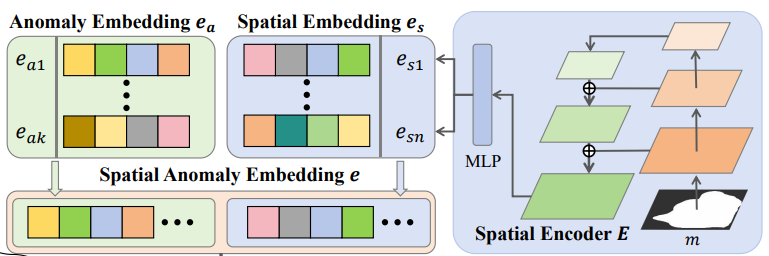
외관 정보를 학습하는 Anomaly Embedding $e_a$와 위치 정보를 학습하는 Spatial Embedding $e_s$를 이용하여 LDM에서 text처럼 정보를 줄 수 있도록 한다. 이를 통해 이상 영역을 집중적으로 학습하면서 다양한 위치에 anomaly가 생길 수 있게 한다고 한다. (아직 완벽하게 이해는 안 감). Anomaly embedding은 k개의 token으로 embedding $e_a$를 초기화하여 최적화하고, 이상 mask의 feature를 추출하여 text embedding 공간으로 이를 mapping한다. 이 때의 loss는 아래와 같다. $e_s$는 총 n개의 embedding이 생성된다.
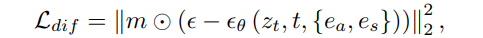
전반적인 framework
각 anomaly type i에 대해서 이상 임베딩 $e_{a,i}$를 사용하여 외관 정보를 추출하며, 모든 이상 카테고리는 공통의 spatial encoder E를 공유한다. Training data에서 얻을 수 있는 image-mask 쌍($x_i, m_i$)에 대해, 먼저 이상 mask를 E에 넣어서 spatial embedding $e_s$를 얻는다. 이후 anomaly embedding과 spatial embedding을 함계 연결하여 e = {$e_a, e_s$}를 얻는다(concat된다).
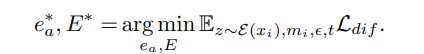
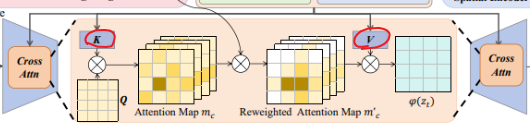
Adaptive Attention Re-Weighting
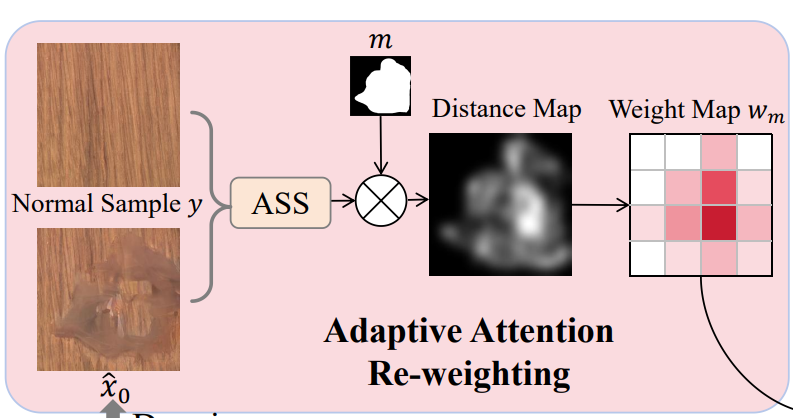
LDM을 통해 데이터를 생성하면, 때때로 전체 mask를 채우지 못한다. (c 그림). 마스크 내에 다수의 이상 영역이 있거마 마스크가 불규칙한 경우에 이러한 경우가 많이 발생한다. 이를 해결하기 위해서 denoising 중에 덜 눈에 띄는 생성된 이상 영역에 더 많은 attention을 할당하여 생성된 이상들과 이상 마스크 사이에 더 나은 정렬을 촉진한다.

| t번 째 denoising 단계에서 $\hat{x}0 = D(p{\theta}(\hat{z}0 | zt, e))$를 계산한다. (D는 LDM의 디코더). |
이후 마스크 m 내에서 $\hat{x}_0$과 y 사이의 픽셀 수준 차이를 계산한다. 차이를 기반으로 weight map $w_m$을 계산한다. 이 때 Adapte Scaling Softmax(ASS)가 적용된다. Re-weighting 과정을 통해 앞서 말한 눈에 띄지 않는 영역까지 가지고 온다.
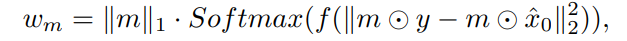
Attention re-weighting
조금 더 재가중되는 메커니즘에 대해서 살펴보자. 앞에서 만든 $w_m$를 이용한다. 이를 이용해 cross-attention을 adaptive하게 control하여 모델이 눈에 덜 띄는 영역을 더 집중하도록 한다. Query는 latent code $z_t$로부터, key와 value는 anomaly embedding e로부터 계산된다. 그리고 $φi$는 U-Net의 intermediate 표현이고 $W^i$는 학습가능하다. Self-attention은 다음과 같은 형식으로 진행된다. RW-Attn(Q, K, V ) = $m^′_ c · V$
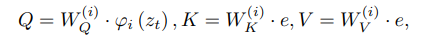
Mask Generation
생성된 embedding $e_m$을 text 조건으로 사용하여 광범위한 mask를 생성할 수 있다. 초기 $e_m$은 k’개의 무작위 토큰으로 초기화한다.
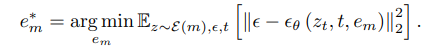
실험
- Dataset :
MVTec데이터셋 사용. 이상 데이터의 1/3만 train, 나머지 2/3은 test - Anomaly embedding : k = 8
- Spatial embedding : n = 4
-
Mask embedding : k’ = 4
- 총 1000개의 이상 image-mask 쌍을 생성한다.
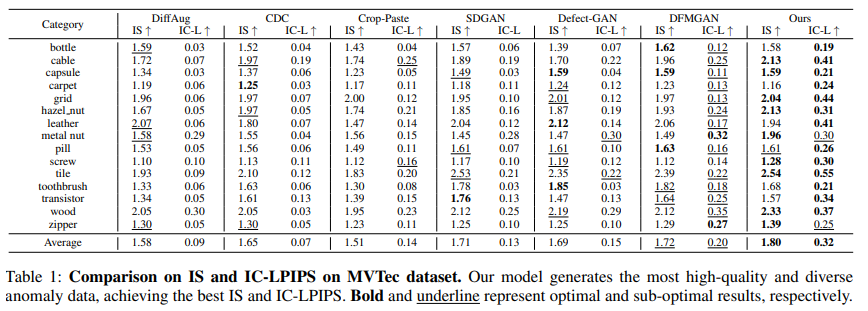
- FID와 KID는 신뢰할 수 없다고 한다. IS와 IC-LPIPS를 이용한다.
- 이상 검사의 성능은 AUROC, AP, F1-max를 사용한다.
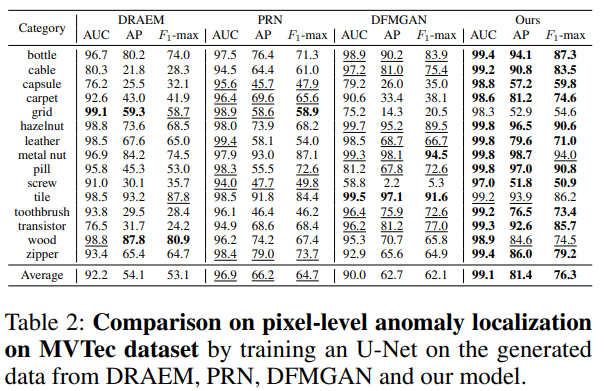
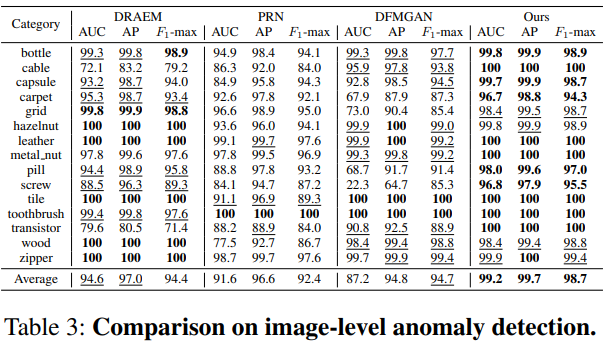
비교 실험
- 특정 이상 유형을 생성할 수 있는 모델들 간의 비교 : 생성 품질과 분류
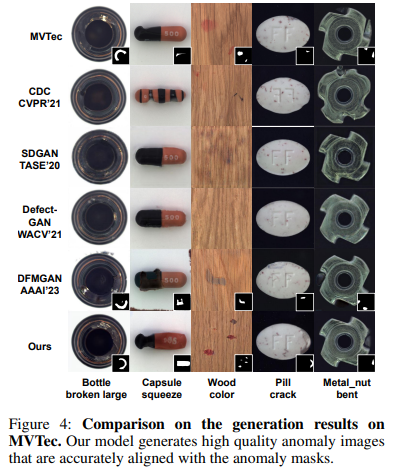
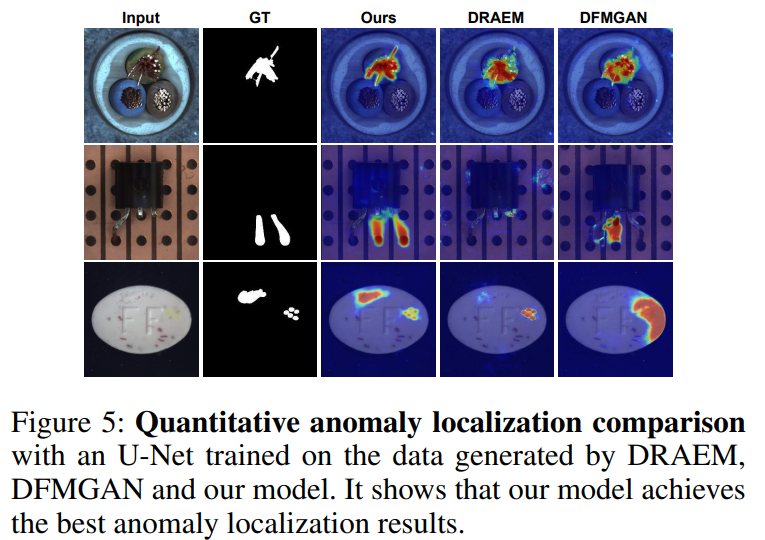
- 이상 image-mask 쌍을 생성할 수 있는 모델들과의 비교 : 이상 탐지와 위치 확인
뒤에 ablation study를 보면 기존의 text inversion은 이상 유형 정보와 함께 이상의 위치를 포착하는 경향이 있어서 생성된 이상이 특정 위치에만 분포된다고 한다. 따라서 $e_a$와 $e_s$ 두 개의 임베딩 공간을 만들어 공간 정보를 분리하였다고 한다. 이를 증명하기 위해서 그림 하나를 통해서 결과를 보여주는데 사실 조금 더 많은 실험이 필요한게 아닌가 싶다. 잘 이해가 가지 않는 느낌..

또다른 추가적인 ablation study를 보면 살짝 이해가 될 것도 같다. $e_s$의 크기를 조절하여 마치 prompt-to-prompt에서 단어를 바꿔주면서 특정 위치에 대한 제어된 이미지 생성처럼, 크기를 달라지게 하는 인자를 모델에 제공해주는 것이다. $e_a$는 이에 따라서 자연스럽게 공간의 정보보다 외형의 정보를 잘 보는? 아 명확하게 와닿지 않는다.

Leave a comment