
Object_detection study
스터디 목표 설정
- 논문 읽기 vs 성능 개선 vs 의료 영역 논문 타겟으로 잡고 개선 시킬 것인지?
- ViT 기반의 논문?
- 각자의 관심 영역 이야기
내 관심 영역
-
최신 모델
- 뭔지 잘 모르겠는데 sota
- Open-Vocabulary DETR with Conditional Matching
- Detecting Twenty-thousand Classes using Image-level Supervision
- with LLM
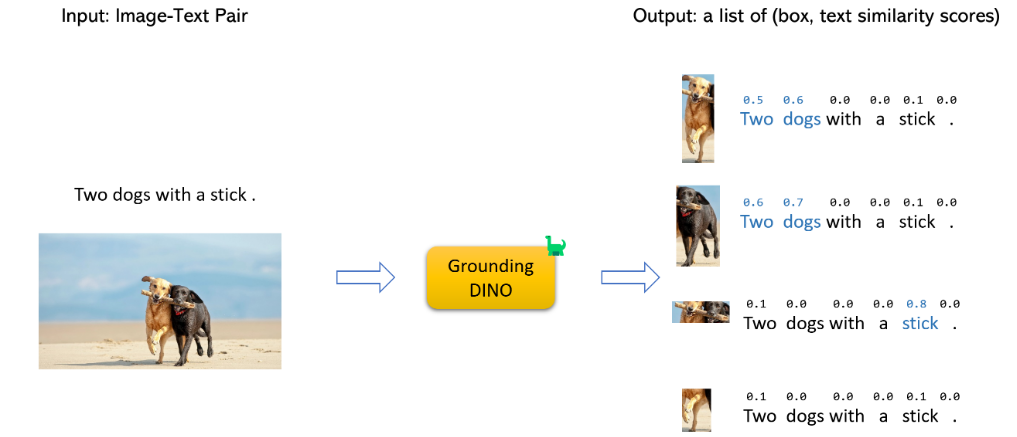
- with Diffusion
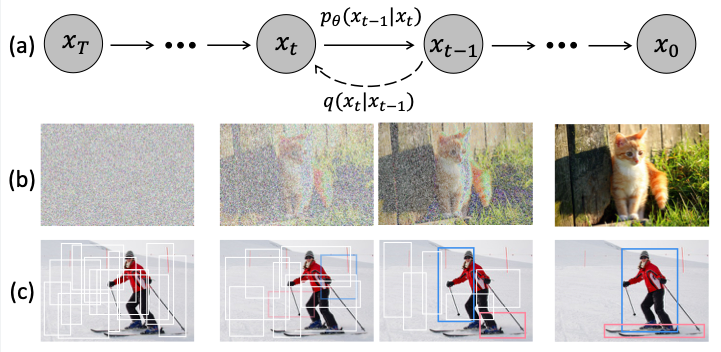
- 뭔지 잘 모르겠는데 sota
-
의료 영상에 적용하는 모델
- X-ray, MRI 등 target 선정
- 예시 [1], [2]
[1] Anatomy-Driven Pathology Detection on Chest X-rays
[2] Medical Phrase Grounding with Region-Phrase Context Contrastive Alignment » 판독문 기반으로 detection 영역 찾기
[3] Finding-Aware Anatomical Tokens for Chest X-Ray Automated Reporting » Detection과 판독문 생성을 같이
ex) 최신 video segmentation에서 sota를 거둔 논문 [1]을 참고해서 [2]를 개선
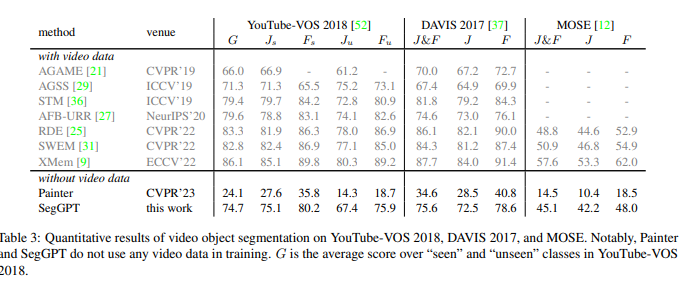
![[image-20231205141807313]](/images/Object_Detection Study/image-20231205141807313.png)
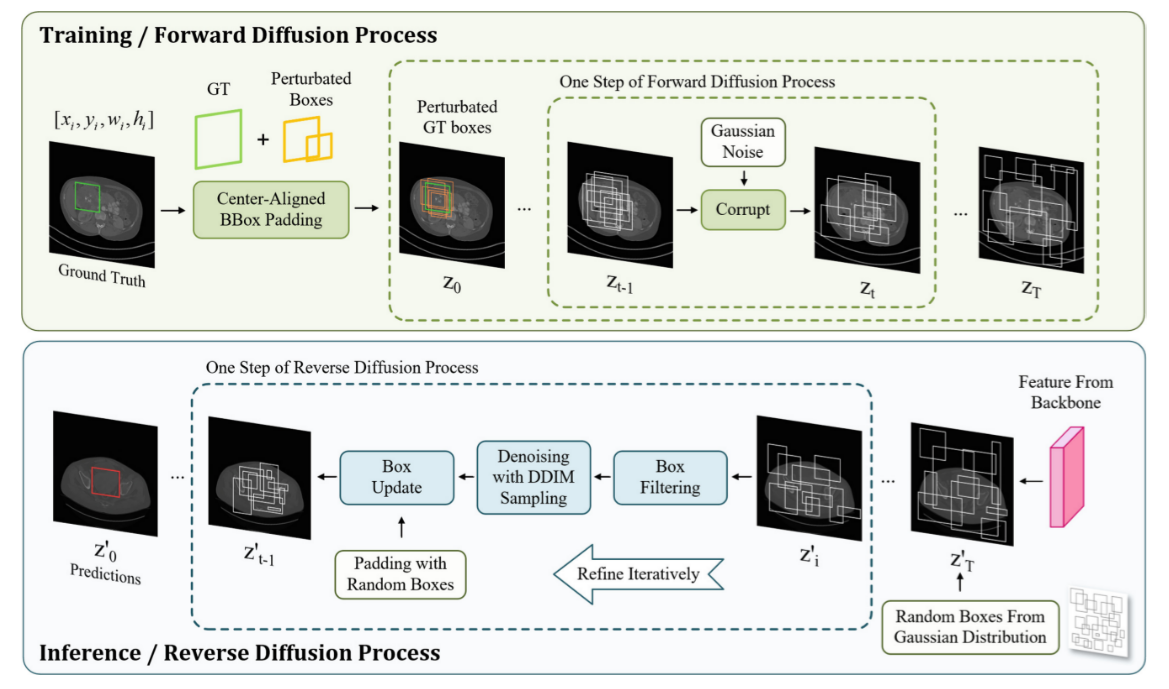
ex) DiffusionDet 같은 형태를 medical에 적용[3]
[1] SegGPT: Segmenting Everything In Context
[2] ACT-Net: Anchor-Context Action Detection in Surgery Videos
[3] DiffULD: Diffusive Universal Lesion Detection
[4] Self- and Semi-supervised Learning for Gastroscopic Lesion Detection
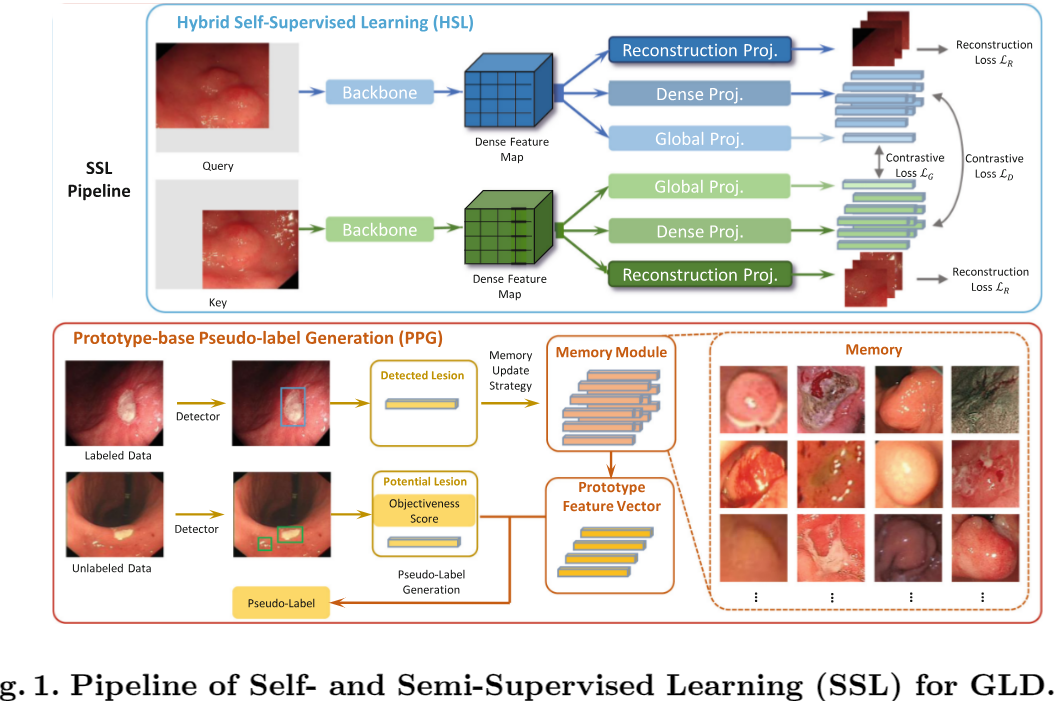
[5] YONA: You Only Need One Adjacent Reference-Frame for Accurate and Fast Video Polyp Detection
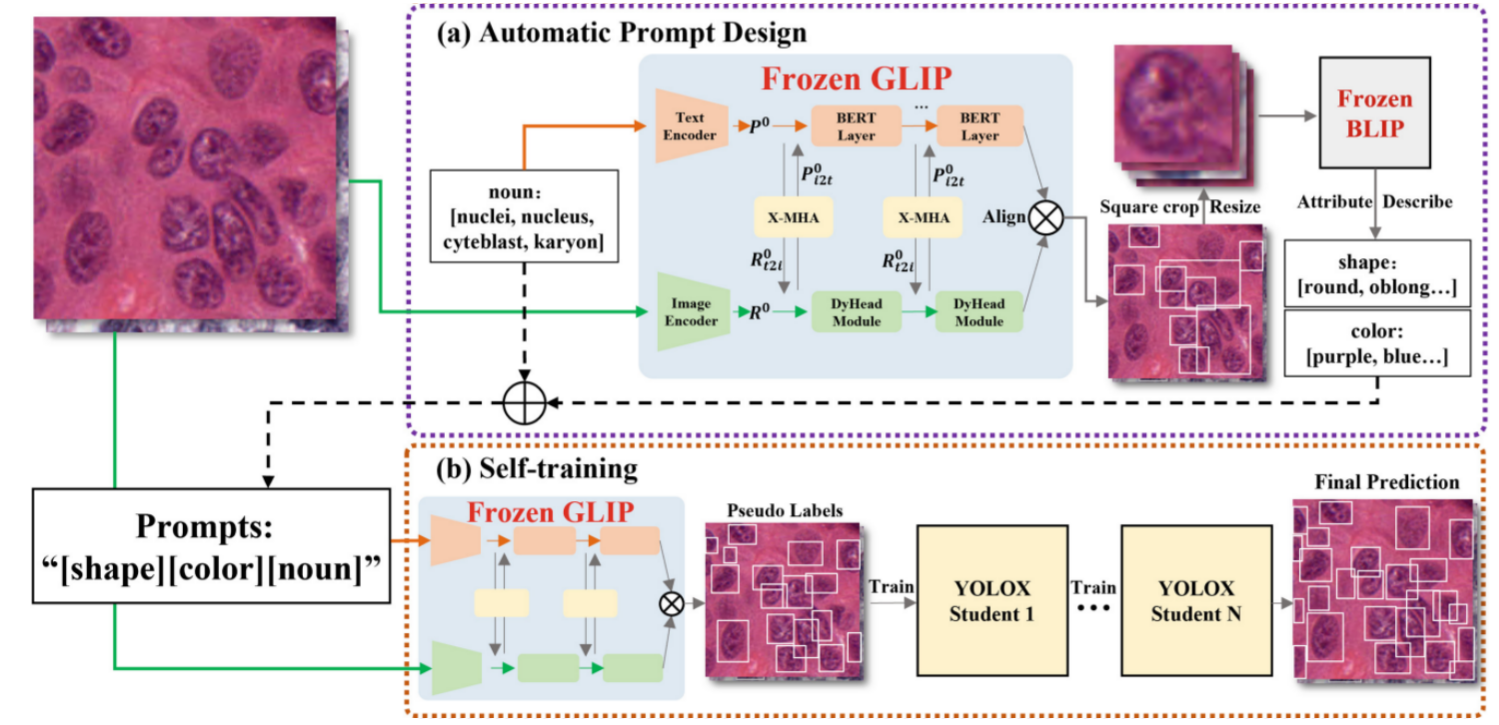
[6] Zero-Shot Nuclei Detection via Visual-Language Pre-trained Models via Visual-Language Pre-trained Models
진행방향 고민
- 각자 논문 선정해서 읽어오기
- task 하나 잡고 개선
Leave a comment